[ 머신러닝 ] KMEans
2023. 9. 11. 18:44ㆍ머신러닝
728x90
1. Clusters
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
from sklearn.datasets import make_blobsX, y = make_blobs(n_samples=100, centers=3, random_state=10)
X = pd.DataFrame(X)
X# 결과

y
--------------------------------------------------------------------------
# 결과
array([2, 2, 1, 0, 1, 1, 0, 2, 1, 0, 0, 1, 1, 2, 2, 1, 0, 1, 0, 1, 0, 2,
1, 2, 0, 1, 1, 1, 1, 0, 2, 1, 1, 0, 2, 2, 2, 1, 1, 1, 2, 0, 2, 2,
1, 0, 0, 0, 2, 0, 1, 2, 0, 0, 2, 0, 1, 2, 0, 0, 1, 1, 2, 2, 2, 0,
0, 2, 2, 2, 1, 0, 1, 1, 2, 1, 1, 2, 0, 0, 0, 1, 0, 1, 2, 1, 2, 0,
2, 2, 0, 0, 0, 2, 2, 2, 1, 0, 0, 0])
---------------------------------------------------------------------------
sns.scatterplot(x=X[0], y=X[1], hue=y)# 결과

from sklearn.cluster import KMeans
km = KMeans(n_clusters=3)
km.fit(X)
-----------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
pred = km.predict(X)
sns.scatterplot(x=X[0], y=X[1], hue=pred)# 결과

km = KMeans(n_clusters=4)
km.fit(X)
pred=km.predict(X)
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
sns.scatterplot(x=X[0], y=X[1], hue=pred)# 결과

km.inertia_
---------------------
# 결과
154.07856318909234
----------------------------------------------------------------------
# 평가값. 하나의 클러스터 안에 중심점으로부터 각각의 데이터 거리를 합한 값
km.inertia_
----------------------------------------------------------------------
# 결과
154.07856318909234
----------------------------------------------------------------------
inertia_list = []
for i in range(2, 11):
km = KMeans(n_clusters=i)
km.fit(X)
inertia_list.append(km.inertia_)
-----------------------------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(sns.lineplot(x=range(2, 11), y=inertia_list)# 결과

2. marketing 데이터셋 살펴보기
mkt_df = pd.read_csv('/content/drive/MyDrive/8. 머신러닝 딥러닝/marketing.csv')
mkt_df# 결과

pd.set_option('display.max_columns', 40)
mkt_df.head()# 결과

mkt_df.info()
------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2240 entries, 0 to 2239
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 2240 non-null int64
1 Year_Birth 2240 non-null int64
2 Education 2240 non-null object
3 Marital_Status 2240 non-null object
4 Income 2216 non-null float64
5 Kidhome 2240 non-null int64
6 Teenhome 2240 non-null int64
7 Dt_Customer 2240 non-null object
8 Recency 2240 non-null int64
9 MntWines 2240 non-null int64
10 MntFruits 2240 non-null int64
11 MntMeatProducts 2240 non-null int64
12 MntFishProducts 2240 non-null int64
13 MntSweetProducts 2240 non-null int64
14 MntGoldProds 2240 non-null int64
15 NumDealsPurchases 2240 non-null int64
16 NumWebPurchases 2240 non-null int64
17 NumCatalogPurchases 2240 non-null int64
18 NumStorePurchases 2240 non-null int64
19 NumWebVisitsMonth 2240 non-null int64
20 Complain 2240 non-null int64
dtypes: float64(1), int64(17), object(3)
memory usage: 367.6+ KB
mkt_df.drop('ID', axis=1, inplace=True)
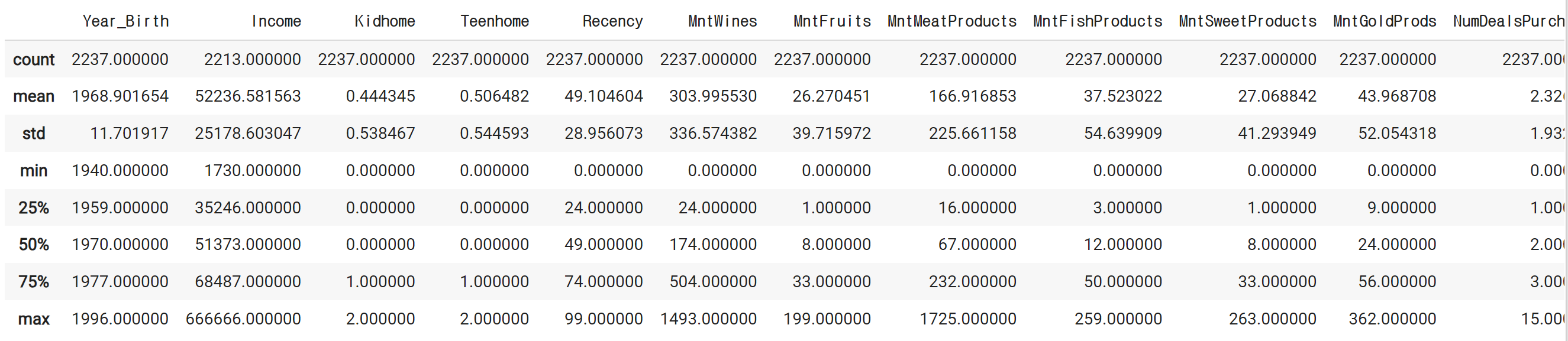
mkt_df.describe()# 결과

mkt_df.sort_values('Year_Birth')# 결과
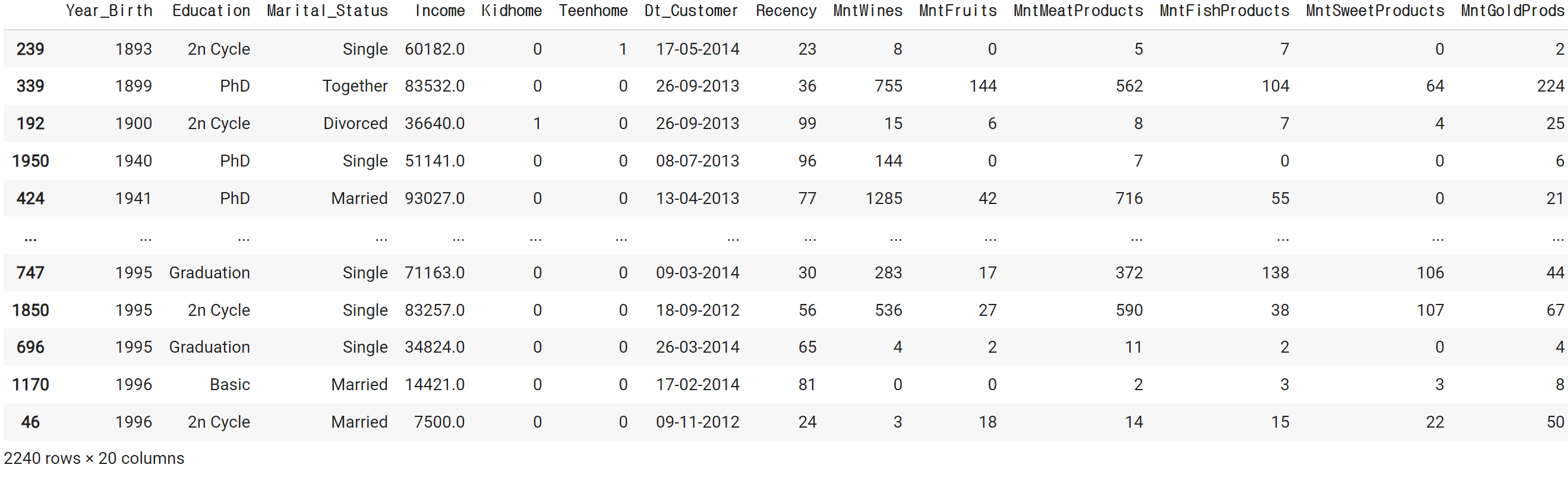
mkt_df = mkt_df[mkt_df['Year_Birth'] > 1900]
mkt_df.describe()# 결과
mkt_df.sort_values('Income', ascending=False)# 결과

mkt_df.isna().mean()
--------------------------------------
# 결과
Year_Birth 0.000000
Education 0.000000
Marital_Status 0.000000
Income 0.010729
Kidhome 0.000000
Teenhome 0.000000
Dt_Customer 0.000000
Recency 0.000000
MntWines 0.000000
MntFruits 0.000000
MntMeatProducts 0.000000
MntFishProducts 0.000000
MntSweetProducts 0.000000
MntGoldProds 0.000000
NumDealsPurchases 0.000000
NumWebPurchases 0.000000
NumCatalogPurchases 0.000000
NumStorePurchases 0.000000
NumWebVisitsMonth 0.000000
Complain 0.000000
dtype: float64# mkt_df = mkt_df[mkt_df['income'] < 200000] NaN이 저장되지 않음
mkt_df = mkt_df[mkt_df['Income'] != 666666]
mkt_df.sort_values('Income', ascending=False)# 결과

mkt_df = mkt_df.dropna()
mkt_df.isna().mean()
----------------------------------
# 결과
Year_Birth 0.0
Education 0.0
Marital_Status 0.0
Income 0.0
Kidhome 0.0
Teenhome 0.0
Dt_Customer 0.0
Recency 0.0
MntWines 0.0
MntFruits 0.0
MntMeatProducts 0.0
MntFishProducts 0.0
MntSweetProducts 0.0
MntGoldProds 0.0
NumDealsPurchases 0.0
NumWebPurchases 0.0
NumCatalogPurchases 0.0
NumStorePurchases 0.0
NumWebVisitsMonth 0.0
Complain 0.0
dtype: float64
-----------------------------------------------
mkt_df.info()
------------------------------------------------
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2212 entries, 0 to 2239
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2212 non-null int64
1 Education 2212 non-null object
2 Marital_Status 2212 non-null object
3 Income 2212 non-null float64
4 Kidhome 2212 non-null int64
5 Teenhome 2212 non-null int64
6 Dt_Customer 2212 non-null object
7 Recency 2212 non-null int64
8 MntWines 2212 non-null int64
9 MntFruits 2212 non-null int64
10 MntMeatProducts 2212 non-null int64
11 MntFishProducts 2212 non-null int64
12 MntSweetProducts 2212 non-null int64
13 MntGoldProds 2212 non-null int64
14 NumDealsPurchases 2212 non-null int64
15 NumWebPurchases 2212 non-null int64
16 NumCatalogPurchases 2212 non-null int64
17 NumStorePurchases 2212 non-null int64
18 NumWebVisitsMonth 2212 non-null int64
19 Complain 2212 non-null int64
dtypes: float64(1), int64(16), object(3)
memory usage: 362.9+ KB
-------------------------------------------------------------
mkt_df['Dt_Customer'] = pd.to_datetime(mkt_df['Dt_Customer'])
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 결과
<ipython-input-53-51c2edf49ec9>:1: UserWarning: Parsing dates in DD/MM/YYYY format when dayfirst=False (the default) was specified. This may lead to inconsistently parsed dates! Specify a format to ensure consistent parsing.
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
mkt_df.info()
---------------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2212 entries, 0 to 2239
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year_Birth 2212 non-null int64
1 Education 2212 non-null object
2 Marital_Status 2212 non-null object
3 Income 2212 non-null float64
4 Kidhome 2212 non-null int64
5 Teenhome 2212 non-null int64
6 Dt_Customer 2212 non-null datetime64[ns]
7 Recency 2212 non-null int64
8 MntWines 2212 non-null int64
9 MntFruits 2212 non-null int64
10 MntMeatProducts 2212 non-null int64
11 MntFishProducts 2212 non-null int64
12 MntSweetProducts 2212 non-null int64
13 MntGoldProds 2212 non-null int64
14 NumDealsPurchases 2212 non-null int64
15 NumWebPurchases 2212 non-null int64
16 NumCatalogPurchases 2212 non-null int64
17 NumStorePurchases 2212 non-null int64
18 NumWebVisitsMonth 2212 non-null int64
19 Complain 2212 non-null int64
dtypes: datetime64[ns](1), float64(1), int64(16), object(2)
memory usage: 362.9+ KB
------------------------------------------------------------------
# 마지막으로 가입된 사람을 기준으로 가입 날짜(달) 구하기
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month) - (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month)
mkt_df['pass_month'] = (mkt_df['Dt_Customer'].dt.year * 12 + mkt_df['Dt_Customer'].dt.month) - (mkt_df['Dt_Customer'].max().year * 12 + mkt_df['Dt_Customer'].max().month)
mkt_df.head()# 결과

mkt_df.drop('Dt_Customer', axis=1, inplace=True)
mkt_df.head()# 결과

# mkt_df['Total_mnt'] = 와인, 과일, 육류, 어류, 단맛, 골드
mkt_df['Total_mnt'] = mkt_df[['MntWines', 'MntFruits', 'MntMeatProducts', 'MntFishProducts', 'MntSweetProducts', 'MntGoldProds']].sum(axis=1)
mkt_df['Children'] = mkt_df[['Kidhome', 'Teenhome']].sum(axis=1)
mkt_df.drop(['Kidhome', 'Teenhome'],axis=1,inplace=True)
mkt_df['Education'].value_counts()
--------------------------------------------------------------------------------------
# 결과
Graduation 1115
PhD 480
Master 365
2n Cycle 198
Basic 54
Name: Education, dtype: int64
---------------------------------------------------------------------------------------
mkt_df['Marital_Status'].value_counts()
----------------------------------------
# 결과
Married 857
Together 571
Single 470
Divorced 231
Widow 76
Alone 3
Absurd 2
YOLO 2
Name: Marital_Status, dtype: int64
-----------------------------------------
mkt_df['Marital_Status'] = mkt_df['Marital_Status'].replace({'Married':'Partner', 'Together':'Partner', 'Single':'Single', 'Divorced':'Single', 'Widow':'Single', 'Alone':'Single', 'Absurd':'Single', 'YOLO':'Single'})
mkt_df['Marital_Status'].value_counts()
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 결과
Partner 1428
Single 784
Name: Marital_Status, dtype: int64
----------------------------------------------------------------
mkt_df = pd.get_dummies(mkt_df,columns=['Education','Marital_Status'])
mkt_df.head()# 결과

3. 스케일링 (Scaling)
- 데이터를 특정한 스케일로 통일하는 것
- 데이터를 모델링하기 전에 거치는 것이 좋음
- 다차원의 값들을 비교 분석하기 쉽게 만들어주며, 자료의 오버플로우나 언더플로우를 방지하며 최적화 과정에서의 안정성 및 수렴 속도를 향상
3-1. 스케일링의 종류
- standardScaler: 평균과 표준편차를 사용
- MInMaxScaler: 최대/최소값이 각각 1과 0이 되도록 스케일링
- RobustScale : 중앙값과 IQR사용, 아웃라이어의 영향을 최소화
movie = {'naver':[2,4,6,8,10],'netflix':[1,2,3,4,5]}
movie = pd.DataFrame(data=movie)
movie# 결과

from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
min_max_scaler = MinMaxScaler()
min_max_movie = min_max_scaler.fit_transform(movie)
pd.DataFrame(min_max_movie,columns=['Naver','Netflix'])# 결과

3-2. 스케일링 적용하기
ss = StandardScaler()
ss.fit_transform(mkt_df)
-----------------------------------------------------------------
# 결과
array([[-1.01835202, 0.28710487, 0.31035323, ..., -0.52643733,
-1.34960312, 1.34960312],
[-1.27478522, -0.26088203, -0.38081349, ..., -0.52643733,
-1.34960312, 1.34960312],
[-0.33453017, 0.9131964 , -0.79551352, ..., -0.52643733,
0.74095857, -0.74095857],
...,
[ 1.03311355, 0.23334696, 1.45077832, ..., -0.52643733,
-1.34960312, 1.34960312],
[-1.10382975, 0.80317156, -1.41756357, ..., -0.52643733,
0.74095857, -0.74095857],
[-1.27478522, 0.04229031, -0.31169682, ..., 1.89956135,
0.74095857, -0.74095857]])
--------------------------------------------------------------------
pd.DataFrame(ss.fit_transform(mkt_df))# 결과

ss_df = pd.DataFrame(ss.fit_transform(mkt_df),columns=mkt_df.columns)
rs = RobustScaler()
rs_df = pd.DataFrame(rs.fit_transform(mkt_df),columns= mkt_df.columns)
rs_df# 결과

mm = MinMaxScaler()
mm_df = pd.DataFrame (mm.fit_transform(mkt_df),columns=mkt_df.columns)
mm_df# 결과
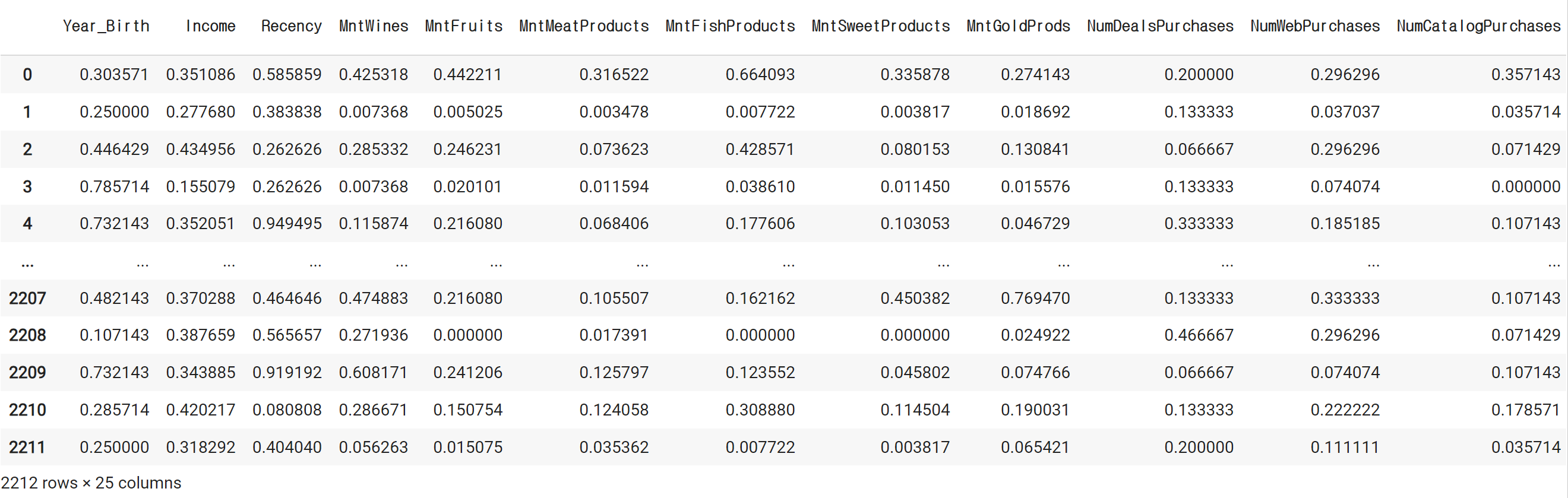
4. KMeans
- KMeans 클러스터링 알고리즘은 n개의 중심점을 찍은 후에, 이 중심점에서 각 점간의 거리의 합이 가장 최소화가 되는 중심점 n의 위치를 찾고, 이 중심점에서 가까운 점들을 중심점을 기준으로 묶는 알고리즘
- 중심점은 각 군집으 데이터의 평균값을 위치로 가지게 됨
- 클러스터의 수를 정해줘야 함
- 중심점을 측정할 때 처음에는 랜덤으러 중심점의 위치를 찾기 때문에 잘못하면 중심점의 점간의 거리가 Global optimum인 최소 값을 찾는게 아니라 중심점이 Local optimum에 수렴하여 잘못된 분류를 할 수 있음
inertia_list =[]
for i in range(2,11):
km = KMeans(n_clusters=i,random_state=10)
km.fit(mm_df)
inertia_list.append(km.inertia_)
---------------------------------------------------------------------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
inertia_list
--------------------------------
# 결과
[2884.52947013434,
2405.195207071574,
2139.189131737316,
1877.7127959780694,
1728.5409997814195,
1554.9009258180042,
1414.241283074918,
1329.5629856639696,
1257.1281654839]
---------------------------------
sns.lineplot(x=range(2, 11), y=inertia_list)# 결과

5 . 실루엣 스코어
- 각 군집 간의 거리가 얼마나 효율적으로 분리 돼있는지를 나타냄
- 다른 군집과의 거리는 떨어져 있고 동일 군집끼리의 데이터는 서로 가깝게 잘 뭉쳐 있다는 의미
- 실루엣 분석은 실루엣 계수를 기반으로 하는데, 실루엣 계수는 개별 데이터가 가지는 군집화 지표
from sklearn.metrics import silhouette_score
score =[]
for i in range(2, 11):
km = KMeans(n_clusters=i, random_state=10)
km.fit(mm_df)
pred = km.predict(mm_df)
score.append(silhouette_score(mm_df, pred))
-----------------------------------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
sns.lineplot(x=range(2,11),y=score)# 결과

km =KMeans(n_clusters=8,random_state=10)
km.fit(mm_df)
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
# 결과
/usr/local/lib/python3.10/dist-packages/sklearn/cluster/_kmeans.py:870: FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
warnings.warn(# 결과

pred=km.predict(mm_df)
pred
------------------------------------------
# 결과
array([2, 2, 7, ..., 2, 5, 3], dtype=int32)
-------------------------------------------
mkt_df['label']=pred
mkt_df# 결과

mkt_df['label'].value_counts()
-----------------------------------------
# 결과
1 431
2 402
3 305
7 282
5 240
0 207
4 175
6 170
Name: label, dtype: int64728x90
반응형
'머신러닝' 카테고리의 다른 글
| [ 머신러닝 ] 파이토치 (0) | 2023.09.11 |
|---|---|
| [ 머신러닝 ] lightGBM (0) | 2023.09.11 |
| [ 머신러닝 ] 랜덤 포레스트 (0) | 2023.09.11 |
| [ 머신러닝 ] 서포트 벡터 머신 (0) | 2023.09.06 |
| [ 머신러닝 ] 로지스틱 회귀 (0) | 2023.09.06 |