머신러닝
[ 머신러닝 ] lightGBM
예진또이(애덤스미스 아님)
2023. 9. 11. 18:14
728x90
1. credit 데이터셋 알아보기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# csv 파일이 구글 드라이브에 있다는 가정
credit_df = pd.read_csv('/content/drive/MyDrive/8. 머신러닝 딥러닝/credit.csv')credit_df# 결과
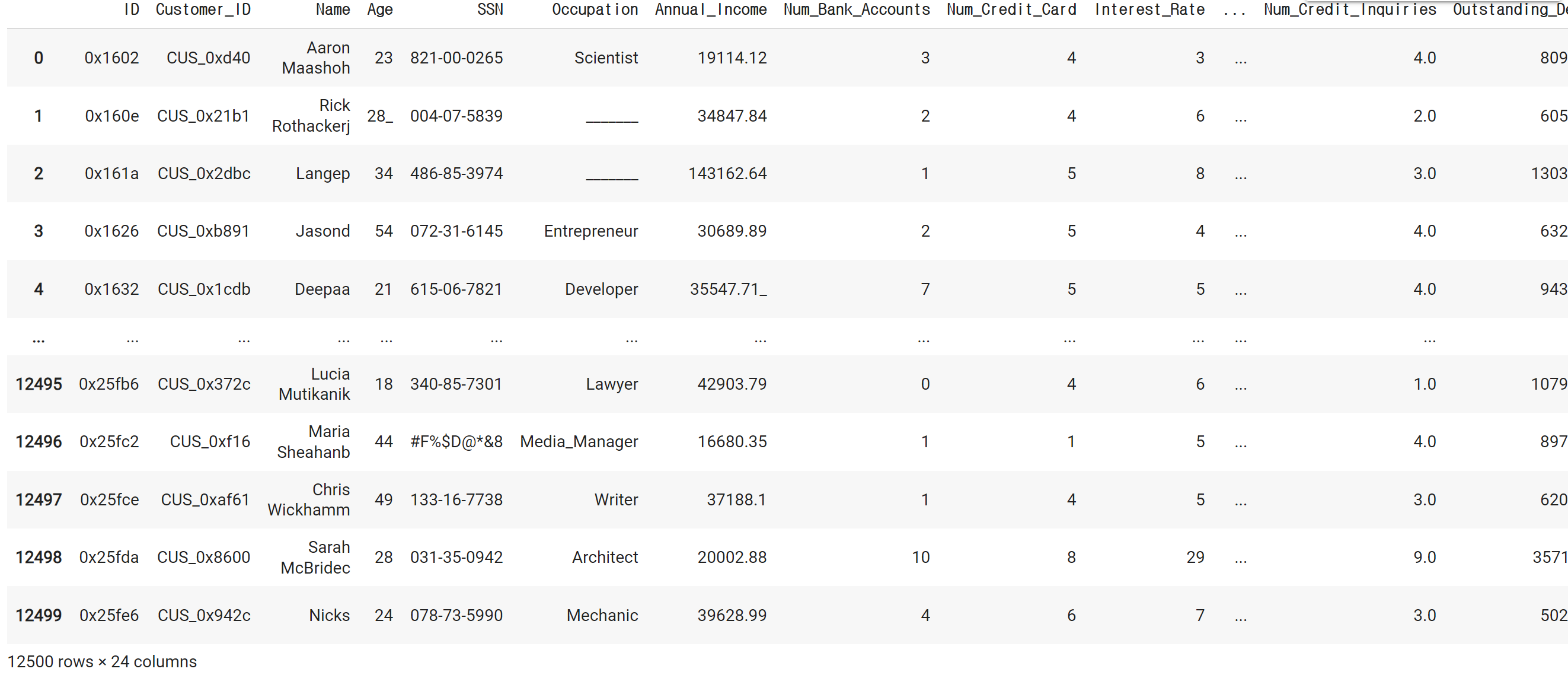
pd.set_option('display.max_columns', 50)
credit_df.head()# 결과

credit_df.info()
-------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12500 entries, 0 to 12499
Data columns (total 24 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ID 12500 non-null object
1 Customer_ID 12500 non-null object
2 Name 11273 non-null object
3 Age 12500 non-null object
4 SSN 12500 non-null object
5 Occupation 12500 non-null object
6 Annual_Income 12500 non-null object
7 Num_Bank_Accounts 12500 non-null int64
8 Num_Credit_Card 12500 non-null int64
9 Interest_Rate 12500 non-null int64
10 Num_of_Loan 12500 non-null object
11 Type_of_Loan 11074 non-null object
12 Delay_from_due_date 12500 non-null int64
13 Num_of_Delayed_Payment 11657 non-null object
14 Num_Credit_Inquiries 12264 non-null float64
15 Outstanding_Debt 12500 non-null object
16 Credit_Utilization_Ratio 12500 non-null float64
17 Credit_History_Age 11387 non-null object
18 Payment_of_Min_Amount 12500 non-null object
19 Total_EMI_per_month 12500 non-null float64
20 Amount_invested_monthly 11935 non-null object
21 Payment_Behaviour 12500 non-null object
22 Monthly_Balance 12366 non-null float64
23 Credit_Score 12500 non-null object
dtypes: float64(4), int64(4), object(16)
memory usage: 2.3+ MB# 부가설명

credit_df.drop(['ID', 'Customer_ID', 'Name', 'SSN'], axis=1, inplace=True)
credit_df.info()
----------------------------------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12500 entries, 0 to 12499
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 12500 non-null object
1 Occupation 12500 non-null object
2 Annual_Income 12500 non-null object
3 Num_Bank_Accounts 12500 non-null int64
4 Num_Credit_Card 12500 non-null int64
5 Interest_Rate 12500 non-null int64
6 Num_of_Loan 12500 non-null object
7 Type_of_Loan 11074 non-null object
8 Delay_from_due_date 12500 non-null int64
9 Num_of_Delayed_Payment 11657 non-null object
10 Num_Credit_Inquiries 12264 non-null float64
11 Outstanding_Debt 12500 non-null object
12 Credit_Utilization_Ratio 12500 non-null float64
13 Credit_History_Age 11387 non-null object
14 Payment_of_Min_Amount 12500 non-null object
15 Total_EMI_per_month 12500 non-null float64
16 Amount_invested_monthly 11935 non-null object
17 Payment_Behaviour 12500 non-null object
18 Monthly_Balance 12366 non-null float64
19 Credit_Score 12500 non-null object
dtypes: float64(4), int64(4), object(12)
memory usage: 1.9+ MBcredit_df['Credit_Score'].value_counts()
------------------------------------------
# 결과
Standard 6943
Poor 3582
Good 1975
Name: Credit_Score, dtype: int64credit_df['Credit_Score'] = credit_df['Credit_Score'].replace({'Poor':0, 'Standard':1, 'Good':2})
credit_df.head()# 결과

credit_df.describe()# 결과

sns.barplot(x='Payment_of_Min_Amount', y='Credit_Score', data=credit_df)# 결과

plt.figure(figsize=(20, 5))
sns.barplot(x='Occupation', y='Credit_Score', data=credit_df)# 결과

# corr(): 각 열 간의 상관 계수를 반환
# 피어슨, 켄달-타우, 스피어먼
plt.figure(figsize=(12, 12))
sns.heatmap(credit_df.corr(), cmap='coolwarm', vmin=-1, vmax=1, annot=True)# 결과

credit_df.info()
------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12500 entries, 0 to 12499
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 12500 non-null object
1 Occupation 12500 non-null object
2 Annual_Income 12500 non-null object
3 Num_Bank_Accounts 12500 non-null int64
4 Num_Credit_Card 12500 non-null int64
5 Interest_Rate 12500 non-null int64
6 Num_of_Loan 12500 non-null object
7 Type_of_Loan 11074 non-null object
8 Delay_from_due_date 12500 non-null int64
9 Num_of_Delayed_Payment 11657 non-null object
10 Num_Credit_Inquiries 12264 non-null float64
11 Outstanding_Debt 12500 non-null object
12 Credit_Utilization_Ratio 12500 non-null float64
13 Credit_History_Age 11387 non-null object
14 Payment_of_Min_Amount 12500 non-null object
15 Total_EMI_per_month 12500 non-null float64
16 Amount_invested_monthly 11935 non-null object
17 Payment_Behaviour 12500 non-null object
18 Monthly_Balance 12366 non-null float64
19 Credit_Score 12500 non-null int64
dtypes: float64(4), int64(5), object(11)
memory usage: 1.9+ MBfor i in credit_df.columns:
if credit_df[i].dtype == 'O':
print(i)
---------------------------------------
# 결과
Age
Occupation
Annual_Income
Num_of_Loan
Type_of_Loan
Num_of_Delayed_Payment
Outstanding_Debt
Credit_History_Age
Payment_of_Min_Amount
Amount_invested_monthly
Payment_Behaviour
-------------------------------------------
credit_df.head()# 결과

for i in ['Age', 'Annual_Income', 'Num_of_Loan', 'Num_of_Delayed_Payment', 'Outstanding_Debt', 'Amount_invested_monthly']:
credit_df[i] = pd.to_numeric(credit_df[i].str.replace('_', ''))
credit_df.info()
---------------------------------------------------------------------------------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12500 entries, 0 to 12499
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 12500 non-null int64
1 Occupation 12500 non-null object
2 Annual_Income 12500 non-null float64
3 Num_Bank_Accounts 12500 non-null int64
4 Num_Credit_Card 12500 non-null int64
5 Interest_Rate 12500 non-null int64
6 Num_of_Loan 12500 non-null int64
7 Type_of_Loan 11074 non-null object
8 Delay_from_due_date 12500 non-null int64
9 Num_of_Delayed_Payment 11657 non-null float64
10 Num_Credit_Inquiries 12264 non-null float64
11 Outstanding_Debt 12500 non-null float64
12 Credit_Utilization_Ratio 12500 non-null float64
13 Credit_History_Age 11387 non-null object
14 Payment_of_Min_Amount 12500 non-null object
15 Total_EMI_per_month 12500 non-null float64
16 Amount_invested_monthly 11935 non-null float64
17 Payment_Behaviour 12500 non-null object
18 Monthly_Balance 12366 non-null float64
19 Credit_Score 12500 non-null int64
dtypes: float64(8), int64(7), object(5)
memory usage: 1.9+ MB# Credit_History_Age의 데이터를 개월로 변경
# 22 Years and 1 Months -> 22 * 12 + 1
# 22 Years and 1
credit_df['Credit_History_Age'] = credit_df['Credit_History_Age'].str.replace(' Months', '')
credit_df['Credit_History_Age'] = pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[0])*12 + pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[1])
credit_df.head()# 결과

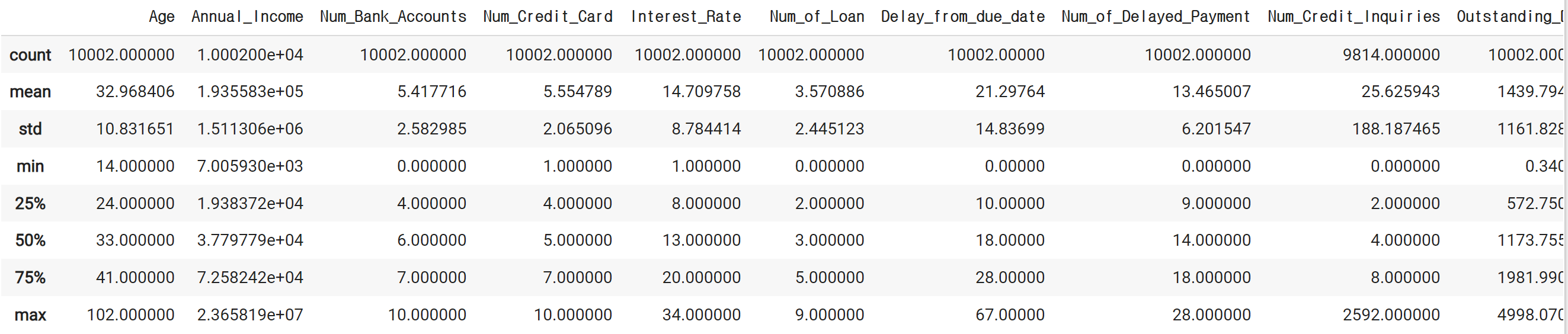
credit_df.describe()# 결과

credit_df[credit_df['Age'] < 0]# 결과


credit_df = credit_df[credit_df['Age'] >= 0]
credit_df.sort_values('Age').tail(30)# 결과

sns.boxplot(y=credit_df['Age'])# 결과

credit_df[credit_df['Age'] > 100].sort_values('Age')# 결과

credit_df = credit_df[credit_df['Age'] < 120]
credit_df.describe()# 결과

len(credit_df[credit_df['Num_Bank_Accounts'] > 30]) / len(credit_df)
--------------------------------------------------------------------
# 결과
0.013029853207982847
---------------------------------------------------------------------
credit_df = credit_df[credit_df['Num_Bank_Accounts'] <= 10]
credit_df.describe()# 결과

len(credit_df[credit_df['Num_Credit_Card'] > 10]) / len(credit_df)
--------------------------------------------------------------------
# 결과
0.022142379679144383
--------------------------------------------------------------------
credit_df = credit_df[credit_df['Num_Credit_Card'] <= 10]
credit_df.describe()# 결과

credit_df = credit_df[credit_df['Interest_Rate'] <= 40]
credit_df.describe()# 결과

len(credit_df[credit_df['Num_of_Loan'] > 10]) / len(credit_df)
--------------------------------------------------------------
# 결과
0.005310350831374598
-----------------------------------------------------------------------------------------
credit_df = credit_df[(credit_df['Num_of_Loan'] <= 10) & (credit_df['Num_of_Loan'] >= 0)]
credit_df.describe()# 결과

credit_df = credit_df[credit_df['Delay_from_due_date'] >= 0]
len(credit_df[credit_df['Num_of_Delayed_Payment'] > 40]) / len(credit_df)
---------------------------------------------------------------------------
# 결과
0.007340122947059363
---------------------------------------------------------------------------
credit_df = credit_df[(credit_df['Num_of_Delayed_Payment'] <= 30) & (credit_df['Num_of_Delayed_Payment'] >= 0)]
credit_df.describe()# 결과
credit_df['Num_Credit_Inquiries'] = credit_df['Num_Credit_Inquiries'].fillna(0)
---------------------------------------------------------------------------------
# 결과
<ipython-input-49-17ca6241ab57>:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
credit_df['Num_Credit_Inquiries'] = credit_df['Num_Credit_Inquiries'].fillna(0)
---------------------------------------------------------------------------------------------------------------------------------------------
credit_df.info()
---------------------------------------------------------------------------------------------------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
Int64Index: 10002 entries, 0 to 12498
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 10002 non-null int64
1 Occupation 10002 non-null object
2 Annual_Income 10002 non-null float64
3 Num_Bank_Accounts 10002 non-null int64
4 Num_Credit_Card 10002 non-null int64
5 Interest_Rate 10002 non-null int64
6 Num_of_Loan 10002 non-null int64
7 Type_of_Loan 8893 non-null object
8 Delay_from_due_date 10002 non-null int64
9 Num_of_Delayed_Payment 10002 non-null float64
10 Num_Credit_Inquiries 10002 non-null float64
11 Outstanding_Debt 10002 non-null float64
12 Credit_Utilization_Ratio 10002 non-null float64
13 Credit_History_Age 9104 non-null float64
14 Payment_of_Min_Amount 10002 non-null object
15 Total_EMI_per_month 10002 non-null float64
16 Amount_invested_monthly 9547 non-null float64
17 Payment_Behaviour 10002 non-null object
18 Monthly_Balance 9893 non-null float64
19 Credit_Score 10002 non-null int64
dtypes: float64(9), int64(7), object(4)
memory usage: 1.6+ MB
------------------------------------------------------------------------------------------
credit_df.isna().sum()
------------------------------------------------------------------------------------------
# 결과
Age 0
Occupation 0
Annual_Income 0
Num_Bank_Accounts 0
Num_Credit_Card 0
Interest_Rate 0
Num_of_Loan 0
Type_of_Loan 1109
Delay_from_due_date 0
Num_of_Delayed_Payment 0
Num_Credit_Inquiries 0
Outstanding_Debt 0
Credit_Utilization_Ratio 0
Credit_History_Age 898
Payment_of_Min_Amount 0
Total_EMI_per_month 0
Amount_invested_monthly 455
Payment_Behaviour 0
Monthly_Balance 109
Credit_Score 0
dtype: int64credit_df.head()# 결과

sns.displot(credit_df['Credit_History_Age'])# 결과

sns.displot(credit_df['Amount_invested_monthly'])# 결과

sns.displot(credit_df['Monthly_Balance'])# 결과

credit_df = credit_df.fillna(credit_df.median())
------------------------------------------------------------------------
# 결과
<ipython-input-56-98962993b203>:1: FutureWarning: The default value of numeric_only in DataFrame.median is deprecated. In a future version, it will default to False. In addition, specifying 'numeric_only=None' is deprecated. Select only valid columns or specify the value of numeric_only to silence this warning.
credit_df = credit_df.fillna(credit_df.median())credit_df.isna().sum()
--------------------------------------
# 결과
Age 0
Occupation 0
Annual_Income 0
Num_Bank_Accounts 0
Num_Credit_Card 0
Interest_Rate 0
Num_of_Loan 0
Type_of_Loan 1109
Delay_from_due_date 0
Num_of_Delayed_Payment 0
Num_Credit_Inquiries 0
Outstanding_Debt 0
Credit_Utilization_Ratio 0
Credit_History_Age 0
Payment_of_Min_Amount 0
Total_EMI_per_month 0
Amount_invested_monthly 0
Payment_Behaviour 0
Monthly_Balance 0
Credit_Score 0
dtype: int64credit_df.head()# 결과

credit_df['Type_of_Loan'] = credit_df['Type_of_Loan'].fillna('No Loan')
credit_df.isna().sum()
-----------------------------------------------------------------------
# 결과
Age 0
Occupation 0
Annual_Income 0
Num_Bank_Accounts 0
Num_Credit_Card 0
Interest_Rate 0
Num_of_Loan 0
Type_of_Loan 0
Delay_from_due_date 0
Num_of_Delayed_Payment 0
Num_Credit_Inquiries 0
Outstanding_Debt 0
Credit_Utilization_Ratio 0
Credit_History_Age 0
Payment_of_Min_Amount 0
Total_EMI_per_month 0
Amount_invested_monthly 0
Payment_Behaviour 0
Monthly_Balance 0
Credit_Score 0
dtype: int64
-------------------------------------------------------------------------
type_list = set(credit_df['Type_of_Loan'].str.split(', ').sum())
type_list
-------------------------------------------------------------------------
# 결과
{'Auto Loan',
'Credit-Builder Loan',
'Debt Consolidation Loan',
'Home Equity Loan',
'Mortgage Loan',
'No Loan',
'Not Specified',
'Payday Loan',
'Personal Loan',
'Student Loan'}
-----------------------------------------------------------------------
for i in type_list:
credit_df[i] = credit_df['Type_of_Loan'].apply(lambda x: 1 if i in x else 0)
credit_df.head()# 결과

credit_df.drop('Type_of_Loan', axis=1, inplace=True)
credit_df.info()
-----------------------------------------------------
# 결과
<class 'pandas.core.frame.DataFrame'>
Int64Index: 10002 entries, 0 to 12498
Data columns (total 29 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Age 10002 non-null int64
1 Occupation 10002 non-null object
2 Annual_Income 10002 non-null float64
3 Num_Bank_Accounts 10002 non-null int64
4 Num_Credit_Card 10002 non-null int64
5 Interest_Rate 10002 non-null int64
6 Num_of_Loan 10002 non-null int64
7 Delay_from_due_date 10002 non-null int64
8 Num_of_Delayed_Payment 10002 non-null float64
9 Num_Credit_Inquiries 10002 non-null float64
10 Outstanding_Debt 10002 non-null float64
11 Credit_Utilization_Ratio 10002 non-null float64
12 Credit_History_Age 10002 non-null float64
13 Payment_of_Min_Amount 10002 non-null object
14 Total_EMI_per_month 10002 non-null float64
15 Amount_invested_monthly 10002 non-null float64
16 Payment_Behaviour 10002 non-null object
17 Monthly_Balance 10002 non-null float64
18 Credit_Score 10002 non-null int64
19 Debt Consolidation Loan 10002 non-null int64
20 Auto Loan 10002 non-null int64
21 Home Equity Loan 10002 non-null int64
22 Payday Loan 10002 non-null int64
23 Credit-Builder Loan 10002 non-null int64
24 Mortgage Loan 10002 non-null int64
25 Not Specified 10002 non-null int64
26 Student Loan 10002 non-null int64
27 Personal Loan 10002 non-null int64
28 No Loan 10002 non-null int64
dtypes: float64(9), int64(17), object(3)
memory usage: 2.3+ MB
--------------------------------------------------------------------
credit_df['Occupation'].value_counts()
---------------------------------------------------------------------
_______ 673
Lawyer 664
Mechanic 646
Scientist 640
Engineer 640
Architect 632
Teacher 624
Developer 621
Entrepreneur 620
Media_Manager 616
Accountant 611
Doctor 608
Musician 607
Journalist 606
Manager 602
Writer 592
Name: Occupation, dtype: int64
--------------------------------------------------------------------------------
credit_df['Occupation'] = credit_df['Occupation'].replace('_______', 'Unknown')
credit_df['Occupation'].value_counts()
--------------------------------------------------------------------------------
# 결과
Unknown 673
Lawyer 664
Mechanic 646
Scientist 640
Engineer 640
Architect 632
Teacher 624
Developer 621
Entrepreneur 620
Media_Manager 616
Accountant 611
Doctor 608
Musician 607
Journalist 606
Manager 602
Writer 592
Name: Occupation, dtype: int64
-----------------------------------------------------------------------------------
credit_df['Payment_of_Min_Amount'].value_counts()
-----------------------------------------------------------------------------------
# 결과
Yes 5315
No 3489
NM 1198
Name: Payment_of_Min_Amount, dtype: int64
------------------------------------------------------------------------------------
credit_df['Payment_Behaviour'].value_counts()
------------------------------------------------------------------------------------
# 결과
Low_spent_Small_value_payments 2505
High_spent_Medium_value_payments 1794
High_spent_Large_value_payments 1453
Low_spent_Medium_value_payments 1376
High_spent_Small_value_payments 1136
Low_spent_Large_value_payments 994
!@9#%8 744
Name: Payment_Behaviour, dtype: int64
-----------------------------------------------------------------------------------
credit_df['Payment_Behaviour'] = credit_df['Payment_Behaviour'].replace('!@9#%8', 'Unknown')
credit_df['Payment_Behaviour'].value_counts()
--------------------------------------------------------------------------------------------
# 결과
Low_spent_Small_value_payments 2505
High_spent_Medium_value_payments 1794
High_spent_Large_value_payments 1453
Low_spent_Medium_value_payments 1376
High_spent_Small_value_payments 1136
Low_spent_Large_value_payments 994
Unknown 744
Name: Payment_Behaviour, dtype: int64
------------------------------------------------------------------------------------------------------------
credit_df = pd.get_dummies(credit_df, columns={'Occupation', 'Payment_of_Min_Amount', 'Payment_Behaviour'})
------------------------------------------------------------------------------------------------------------
# 결과
<ipython-input-75-6ba6af3d5be1>:1: FutureWarning: Passing a set as an indexer is deprecated and will raise in a future version. Use a list instead.
credit_df = pd.get_dummies(credit_df, columns={'Occupation', 'Payment_of_Min_Amount', 'Payment_Behaviour'})
credit_df.head()# 결과

from sklearn.model_selection import train_test_split
len(credit_df)
----------------------------------------------------
# 결과
10002
-------------------------------------------------------------------------------------------------------------------------------------------------------
X_train, X_test, y_train, y_test = train_test_split(credit_df.drop('Credit_Score', axis=1), credit_df['Credit_Score'], test_size=0.2, random_state=10)2. lightGBM(LGBM)
- 트리기반 학습 알고리즘인 gradient boosting 방식의 프레임워크
- 의사결정나무, 랜덤포레스트는 균형 트리 분할(level wise) 방식이라면, LGBM은 리프 중심 트리 분할(leaf wise)
- GBM(Gradient Boosting): 모델1을 통해 y를 예측하고, 모델2에 데이터를 넣어 y를 예측, 모델3에 넣어 y를 예측하는 방식
- 학습하는데 걸리는 시간이 적음(빠른 속도)
- 메모리 사용량이 상대적으로 적은편
- 적은 데이터셋을 사용할 경우 과적합 가능성이 매우 큼(일반적으로 데이터가 10000개 이상은 사용해야 함)
from lightgbm import LGBMClassifier
base_model = LGBMClassifier(random_state=10)
base_model.fit(X_train, y_train)# 결과

pred1 = base_model.predict(X_test)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_score
accuracy_score(y_test, pred1)
-------------------------------
# 결과
0.7351324337831084
-------------------------------
confusion_matrix(y_test, pred1)
-------------------------------
# 결과
array([[407, 148, 27],
[145, 896, 91],
[ 3, 116, 168]])
print(classification_report(y_test, pred1))
--------------------------------------------------------
# 결과
precision recall f1-score support
0 0.73 0.70 0.72 582
1 0.77 0.79 0.78 1132
2 0.59 0.59 0.59 287
accuracy 0.74 2001
macro avg 0.70 0.69 0.69 2001
weighted avg 0.73 0.74 0.73 2001
----------------------------------------------------------
proba1 = base_model.predict_proba(X_test)
proba1
----------------------------------------------------------
# 결과
array([[6.98737764e-02, 8.38143193e-01, 9.19830307e-02],
[8.50755391e-01, 1.49084385e-01, 1.60223719e-04],
[2.74240729e-03, 9.96809944e-01, 4.47648956e-04],
...,
[8.60948233e-01, 1.38960947e-01, 9.08196360e-05],
[8.96972732e-01, 1.02822925e-01, 2.04342759e-04],
[6.65766332e-02, 2.29493501e-01, 7.03929866e-01]])
-----------------------------------------------------------
roc_auc_score(y_test, proba1, multi_class='ovr')
------------------------------------------------------------
# 결과
0.89725664252795173. RandomizedSearchCV
- 분류기를 결정하고 해당 분류기의 최적의 하이퍼 파라미터를 찾기 위한 방법
- 튜닝하고싶은 파라미터를 지정하여 파라미터 값의 범위를 정하고, n_iter값을 설정하여 Random하게 조합하여 반복 적
# n_estimators: 반복 수행하는 트리으 갯수(기본값: 100), 값을 크게 지정하면 학습시간도 오래걸리며, 과적합이 발생할 수 있음
# max_depth: 트리의 최대깊이(기본값:-1)
# learning_rate: 학습률(기본값:0.1)
params = {
'n_estimators':[100, 300, 500, 1000],
'max_depth':[-1, 30, 50, 100],
'num_leaves':[5, 10, 20, 50],
'learning_rate':[0.01, 0.05, 0.1, 0.5]
}
------------------------------------------------------------------------------------------------------------------
lgbm = LGBMClassifier(random_state=10)
from sklearn.model_selection import RandomizedSearchCV
rand_lgbm = RandomizedSearchCV(lgbm, params, n_iter=30, random_state=10)
rand_lgbm.fit(X_train, y_train)
---------------------------------------------------------------------------
# 결과
rand_lgbm.cv_results_
----------------------------------------------------------------------
# 결과
{'mean_fit_time': array([ 4.5658648 , 4.21779943, 0.22191768, 0.90757222, 1.59192586,
2.26492696, 2.47405806, 0.32317824, 2.41929116, 2.22137256,
0.77717876, 1.22200518, 11.07079234, 3.06908298, 0.99368539,
1.11443849, 2.51906099, 4.51780829, 2.53231006, 4.29130096,
0.2664588 , 2.75201817, 1.99363923, 22.17760978, 6.7546977 ,
4.74051032, 2.86759224, 1.2348238 , 1.23866282, 3.96955628]),
'std_fit_time': array([1.29296252, 3.6896416 , 0.00681215, 0.01657379, 0.94553769,
0.9201947 , 0.94495989, 0.00780823, 0.88083762, 0.93799943,
0.02406204, 0.92760223, 3.72010351, 3.42336473, 0.54657991,
0.02758457, 0.93683229, 1.09257222, 0.95112682, 1.6993746 ,
0.01278817, 2.54665735, 1.76883832, 6.74077018, 3.23025037,
1.16056574, 0.87981611, 0.9346451 , 0.03268804, 1.28097227]),
'mean_score_time': array([0.19462848, 0.06362696, 0.01226988, 0.06756458, 0.05720692,
0.13102612, 0.10405111, 0.01214552, 0.15181932, 0.09941339,
0.01983519, 0.04295268, 0.56661935, 0.07857223, 0.03669739,
0.06129651, 0.09993787, 0.16018553, 0.16217937, 0.06546946,
0.01431675, 0.08456359, 0.0371521 , 0.65228119, 0.26577258,
0.27799759, 0.08685555, 0.03979492, 0.08403063, 0.19596457]),
'std_score_time': array([0.01524097, 0.02729711, 0.00133985, 0.01082821, 0.0013098 ,
0.00354922, 0.00516856, 0.00165941, 0.0431668 , 0.00593107,
0.00348709, 0.00921069, 0.26958653, 0.03775454, 0.0143277 ,
0.00348675, 0.00236711, 0.00683878, 0.05041467, 0.02363663,
0.00155732, 0.04569411, 0.0135447 , 0.2214836 , 0.10086701,
0.12464238, 0.00336158, 0.00205019, 0.00277391, 0.03762538]),
'param_num_leaves': masked_array(data=[50, 20, 5, 5, 20, 5, 20, 10, 5, 50, 50, 10, 50, 20, 5,
20, 50, 50, 5, 50, 10, 5, 5, 50, 10, 50, 50, 10, 10,
10],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_n_estimators': masked_array(data=[500, 300, 100, 500, 300, 1000, 500, 100, 1000, 300,
100, 300, 1000, 300, 300, 300, 300, 500, 1000, 100,
100, 500, 300, 1000, 1000, 1000, 300, 300, 500, 1000],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_max_depth': masked_array(data=[30, 50, 30, 30, 50, 50, 30, 100, -1, 30, 50, 50, 100,
100, 30, 30, 30, 100, 100, 30, 30, 100, 100, 100, 100,
-1, 100, 30, 100, -1],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object),
'param_learning_rate': masked_array(data=[0.05, 0.01, 0.1, 0.1, 0.05, 0.5, 0.01, 0.01, 0.05, 0.5,
0.01, 0.5, 0.05, 0.5, 0.1, 0.5, 0.05, 0.01, 0.1, 0.5,
0.5, 0.01, 0.5, 0.01, 0.01, 0.5, 0.01, 0.1, 0.1, 0.5],
mask=[False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False, False, False,
False, False, False, False, False, False],
fill_value='?',
dtype=object),
'params': [{'num_leaves': 50,
'n_estimators': 500,
'max_depth': 30,
'learning_rate': 0.05},
{'num_leaves': 20,
'n_estimators': 300,
'max_depth': 50,
'learning_rate': 0.01},
{'num_leaves': 5,
'n_estimators': 100,
'max_depth': 30,
'learning_rate': 0.1},
{'num_leaves': 5,
'n_estimators': 500,
'max_depth': 30,
'learning_rate': 0.1},
{'num_leaves': 20,
'n_estimators': 300,
'max_depth': 50,
'learning_rate': 0.05},
{'num_leaves': 5,
'n_estimators': 1000,
'max_depth': 50,
'learning_rate': 0.5},
{'num_leaves': 20,
'n_estimators': 500,
'max_depth': 30,
'learning_rate': 0.01},
{'num_leaves': 10,
'n_estimators': 100,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 5,
'n_estimators': 1000,
'max_depth': -1,
'learning_rate': 0.05},
{'num_leaves': 50,
'n_estimators': 300,
'max_depth': 30,
'learning_rate': 0.5},
{'num_leaves': 50,
'n_estimators': 100,
'max_depth': 50,
'learning_rate': 0.01},
{'num_leaves': 10,
'n_estimators': 300,
'max_depth': 50,
'learning_rate': 0.5},
{'num_leaves': 50,
'n_estimators': 1000,
'max_depth': 100,
'learning_rate': 0.05},
{'num_leaves': 20,
'n_estimators': 300,
'max_depth': 100,
'learning_rate': 0.5},
{'num_leaves': 5,
'n_estimators': 300,
'max_depth': 30,
'learning_rate': 0.1},
{'num_leaves': 20,
'n_estimators': 300,
'max_depth': 30,
'learning_rate': 0.5},
{'num_leaves': 50,
'n_estimators': 300,
'max_depth': 30,
'learning_rate': 0.05},
{'num_leaves': 50,
'n_estimators': 500,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 5,
'n_estimators': 1000,
'max_depth': 100,
'learning_rate': 0.1},
{'num_leaves': 50,
'n_estimators': 100,
'max_depth': 30,
'learning_rate': 0.5},
{'num_leaves': 10,
'n_estimators': 100,
'max_depth': 30,
'learning_rate': 0.5},
{'num_leaves': 5,
'n_estimators': 500,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 5,
'n_estimators': 300,
'max_depth': 100,
'learning_rate': 0.5},
{'num_leaves': 50,
'n_estimators': 1000,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 10,
'n_estimators': 1000,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 50,
'n_estimators': 1000,
'max_depth': -1,
'learning_rate': 0.5},
{'num_leaves': 50,
'n_estimators': 300,
'max_depth': 100,
'learning_rate': 0.01},
{'num_leaves': 10,
'n_estimators': 300,
'max_depth': 30,
'learning_rate': 0.1},
{'num_leaves': 10,
'n_estimators': 500,
'max_depth': 100,
'learning_rate': 0.1},
{'num_leaves': 10,
'n_estimators': 1000,
'max_depth': -1,
'learning_rate': 0.5}],
'split0_test_score': array([0.73329169, 0.73016864, 0.7339163 , 0.73891318, 0.73454091,
0.72517177, 0.72767021, 0.71205497, 0.73766396, 0.73266708,
0.71767645, 0.71642723, 0.7339163 , 0.72267333, 0.74203623,
0.72267333, 0.7339163 , 0.72891943, 0.7339163 , 0.72329794,
0.72829482, 0.7339163 , 0.72392255, 0.73516552, 0.73079325,
0.72829482, 0.72517177, 0.7270456 , 0.72579638, 0.72517177]),
'split1_test_score': array([0.725 , 0.741875, 0.754375, 0.740625, 0.7325 , 0.718125,
0.745625, 0.736875, 0.741875, 0.72125 , 0.735 , 0.728125,
0.72875 , 0.723125, 0.741875, 0.723125, 0.7275 , 0.738125,
0.733125, 0.725 , 0.725625, 0.76 , 0.7275 , 0.7325 ,
0.744375, 0.720625, 0.74 , 0.73625 , 0.72125 , 0.71375 ]),
'split2_test_score': array([0.738125, 0.7525 , 0.7425 , 0.725 , 0.7275 , 0.726875,
0.743125, 0.719375, 0.725 , 0.735 , 0.7325 , 0.731875,
0.736875, 0.73625 , 0.7325 , 0.73625 , 0.734375, 0.74625 ,
0.730625, 0.73875 , 0.7325 , 0.741875, 0.735 , 0.7375 ,
0.741875, 0.738125, 0.738125, 0.734375, 0.73875 , 0.72875 ]),
'split3_test_score': array([0.73125 , 0.7475 , 0.735625, 0.72875 , 0.73 , 0.715625,
0.745625, 0.726875, 0.73 , 0.7275 , 0.733125, 0.716875,
0.734375, 0.71125 , 0.73125 , 0.71125 , 0.731875, 0.73625 ,
0.723125, 0.731875, 0.71875 , 0.73375 , 0.721875, 0.729375,
0.738125, 0.725 , 0.7475 , 0.72625 , 0.72125 , 0.71375 ]),
'split4_test_score': array([0.725625, 0.731875, 0.73 , 0.72625 , 0.72625 , 0.715625,
0.73125 , 0.728125, 0.725 , 0.713125, 0.7325 , 0.72625 ,
0.72625 , 0.730625, 0.72875 , 0.730625, 0.7225 , 0.730625,
0.719375, 0.72125 , 0.721875, 0.728125, 0.725625, 0.729375,
0.740625, 0.718125, 0.735625, 0.726875, 0.720625, 0.71125 ]),
'mean_test_score': array([0.73065834, 0.74078373, 0.73928326, 0.73190764, 0.73015818,
0.72028435, 0.73865904, 0.72466099, 0.73190779, 0.72590842,
0.73016029, 0.72391045, 0.73203326, 0.72478467, 0.73528225,
0.72478467, 0.73003326, 0.73603389, 0.72803326, 0.72803459,
0.72540896, 0.73953326, 0.72678451, 0.7327831 , 0.73915865,
0.72603396, 0.73728435, 0.73015912, 0.72553428, 0.71853435]),
'std_test_score': array([0.00490687, 0.00866736, 0.00856124, 0.00655385, 0.00306781,
0.00480428, 0.00765039, 0.00840163, 0.0068052 , 0.00794967,
0.00630883, 0.00619945, 0.00391658, 0.00843757, 0.00558123,
0.00843757, 0.00448304, 0.00614264, 0.00576731, 0.00643807,
0.004806 , 0.01113118, 0.00450876, 0.00320111, 0.004643 ,
0.00698831, 0.00723753, 0.00425754, 0.00686346, 0.00703216]),
'rank_test_score': array([13, 1, 3, 12, 16, 29, 5, 27, 11, 22, 14, 28, 10, 25, 8, 25, 17,
7, 19, 18, 24, 2, 20, 9, 4, 21, 6, 15, 23, 30], dtype=int32)}# 결과
rand_lgbm.best_params_
--------------------------------------------------------------------------------
# 결과
{'num_leaves': 20, 'n_estimators': 300, 'max_depth': 50, 'learning_rate': 0.01}
---------------------------------------------------------------------------------
lgbm =LGBMClassifier(random_state=10,num_leaves=20,n_estomators=300,max_depth=50,learning_rate=0.01)
lgbm.fit(X_train,y_train)# 결과

proba = lgbm.predict_proba(X_test)
proba = lgbm.predict_proba(X_test)
roc_auc_score(y_test, proba, multi_class='ovr')
-------------------------------------------------
# 결과
0.9011382504287848728x90
반응형