[ 자연어 처리 ] ELMO
2023. 9. 12. 02:09ㆍ자연어 처리
728x90
1.ELMo(EMbedding from Language Model)
- 2018년에 논문에서 제안된 새로운 워드 임베딩 방법론
- 언어 모델로 하는 임베딩을 의미
- ELMo의 가장 큰 특징은 사전 훈련된 언어 모델(Pre-Trained Langugae Model)
1-1. 기존 워드 임베딩의 한계
- 주변 문맥 정보를 활용하여 단어를 벡터로 표현하는 방법
- 같은 표기의 단어를 문맥에 따라 다르게 임베딩 할 수 없음
1-2. ELMo의 특징
- 사전 학습된 단어 표현을 사용했다는 것
- 사전학습은 대량의 자연어 코퍼스를 미리 학습하여, 자연어 코퍼스 안에 포함된 일반화된 언어 특성들을 모델의 파라미터 안에 함축하는 방법
- 기존 논문에서도 일반화된 언어 특성들을 고려하기 위해 사전 학습된 단어 표현들을 사용했으나 문법이나 문맥 내 의미, 문장의 다의성을 학습한 고품질의 단어 표현을 얻는 것은 어려운 일이였음
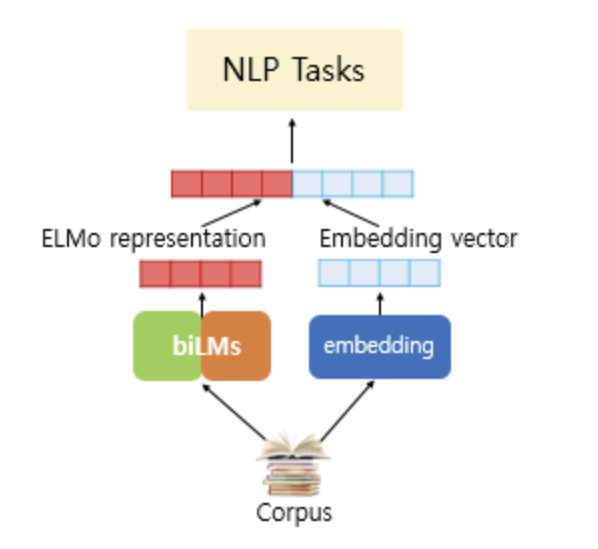
- ELMo의 단어 표현은 문장을 구성하는 각각의 단어 토큰이 전체 입력 문장, 즉 문맥을 고려하는 정보들을 표현 내에 압축한다는 점에서 전통적인 단어 임베딩과 다름
- ELMo의 단어 벡터는 LSTM의 각 layer에서 나온 hidden representation들을 종합한 표현
1-3. biLM(bidirectional Language Model)
- ELMo는 biLM이라는 구조를 사용
- 기존의 Seq2Seq 같은 언어 모델에서는 학습이 한 방향으로 진행되는데, 이렇게되면 문맥을 방향으로만 고려하여 압축된 표현 출력을 반환
- biLM은 N개의 tokens으로 이루어진 입력 문장을 양방향(foward,backward)의 언어 모델링을 통해 문맥적인 표현을 반영하여 해당 입력 문장의 확률을 예측
- ELMo는 기본적으로 LSTM을 사용하여 biLM을 구성 이러한 biLSTM Layer들에서 나오는 각각의 벡터 표현들을 선형 결합하는 방법으로 각각의 단어를 표현
1-4. ELMo 학습 방법
- 특정 자연어처리 작업을 수행하기 위한 사전 학습된 biLM을 목표로 함
- 사존 학습된biLM이 있다면, 지도학습 형태의 다운스트림 작업을 수행하기 위한 언어 모델이 있을때, biLM을 학습하는 방법은 아래와 같음
- 사전 학습된 biLM에 원하는 자연어처리 작업의 학습 데이터셋 문장들을 통과시켜서 문장을 구성하는 각각의 단어 토큰 k에 대한 layer representation을 계산
- biLM에서는 양방향 학습으로 총 L개의 layer에 대해 2L + 1개의 layer representation을 얻을 수 있으므로, 이들을 모두 계산한 후에 biLM의 모든 파라미터를 freeze
- ELMo를 추가한 지도학습 다운스트림 작업을 수행하는 모델을 학습하여 softmax 가중치를 얻을 수 있음
1-5. ELMo 요약
- ELMo는 기존의 단어 임베딩 구조가 문맥의 정보를 충분히 반영하지 못한다는 한계를 지적
- 한계를 해결하기 위해 양방향 학습이 가능한 biLM으로부터 문맥 내 정보를 충분히 반영하는 문장 벡터 표현을 학습하는 일반적인 방법을 소개
- 넓은 범위의 NLP 문제들에서 ELMo를 적용했을 때 많은 성능 향상을 가져옴
- 학습데이터가 작을수록 ELMo를 사용하면 더 효율적인 학습이 가
728x90
반응형
'자연어 처리' 카테고리의 다른 글
| [ 자연어 처리 ] GPT (0) | 2023.09.12 |
|---|---|
| [ 자연어 처리 ] 트랜스포머 (0) | 2023.09.12 |
| [ 자연어 처리 ] Seq2Seq (1) | 2023.09.12 |
| [ 자연어 처리 ] 임베딩 시각화 (0) | 2023.09.12 |
| [ 자연어 처리 ] 워드 임베딩 (0) | 2023.09.12 |