[데이터 분석] CSV 파일 다루기/ 데이터 프레임 기본 정보 알아보기
2023. 6. 25. 21:37ㆍ데이터 분석
728x90
CSV 파일이란?
* CSV(Comma Separated Value)의 약자로 데이터를 쉼표로 구분한 파일
* 엑셀로 로딩할 수 있지만 쉼표로 구분된 CSV가 더 가볍기 때문에 데이터로 많이 사용됨
* 공공데이터 포털에서도 CSV 포맷의 파일을 제공
☑️ 일반 CSV 파일 읽어오기
pd.read_csv( 'CSV파일 경로' )
☑️ 엑셀 파일 읽어오기
pd.read_excel( '파일경로' )
데이터 프레임 기본정보 알아보기
# CSV 파일 가져오기
df = pd.read_csv('http://bit.ly/ds-korean-idol')
# 가져온 파일 표 보기
df🌀 결과

# 타입 알아보기
type(df)
--------------------------------
▶ pandas.core.frame.DataFrame# info(): 기본적인 행(row). 열(column)의 정보와 데이터 타입을 반환
df.info()
---------------------------------------------------------------------
# 결과
▶ <class 'pandas.core.frame.DataFrame'>
RangeIndex: 15 entries, 0 to 14
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 이름 15 non-null object
1 그룹 14 non-null object
2 소속사 15 non-null object
3 성별 15 non-null object
4 생년월일 15 non-null object
5 키 13 non-null float64
6 혈액형 15 non-null object
7 브랜드평판지수 15 non-null int64
dtypes: float64(1), int64(1), object(6)
memory usage: 1.1+ KB1️⃣ 열(column)다루기
df.columns
--------------------------------------------------------------------------------------------------------
# 결과
▶ Index(['이름', '그룹', '소속사', '성별', '생년월일', '키', '혈액형', '브랜드평판지수'], dtype='object')# 새로운 컬럼 만들기
new_column = ['name','group','company','gender','birthday','height','blood','brand']
df.columns = new_column# 바뀐 새로운 컬럼 확인하기
df🌀 결과

2️⃣ 통계정보 알아보기
#describe(): 통계 정보를 출력
df.describe()🌀 결과

df.describe(include=object)🌀 결과

3️⃣ 형태(shape) 알아보기
df.shape
-------------------
# 결과
▶ (15, 8)4️⃣ 원하는 개수의 데이터 보기
* head( ): 상위 5개의 row를 출력
* head(n): 상위 n개의 row를 출력
* tail( ): 하위 5개의 row를 출력
* tail(n): 하위 n개의 row를 출력
df.head()🌀 결과

df.head(7)🌀 결과

df.tail(7)🌀 결과

df.tail()🌀 결과

# index로 오름차순 정렬
df.sort_index()🌀 결과

# index로 내림차순 정렬
df.sort_index(ascending=False)🌀 결과
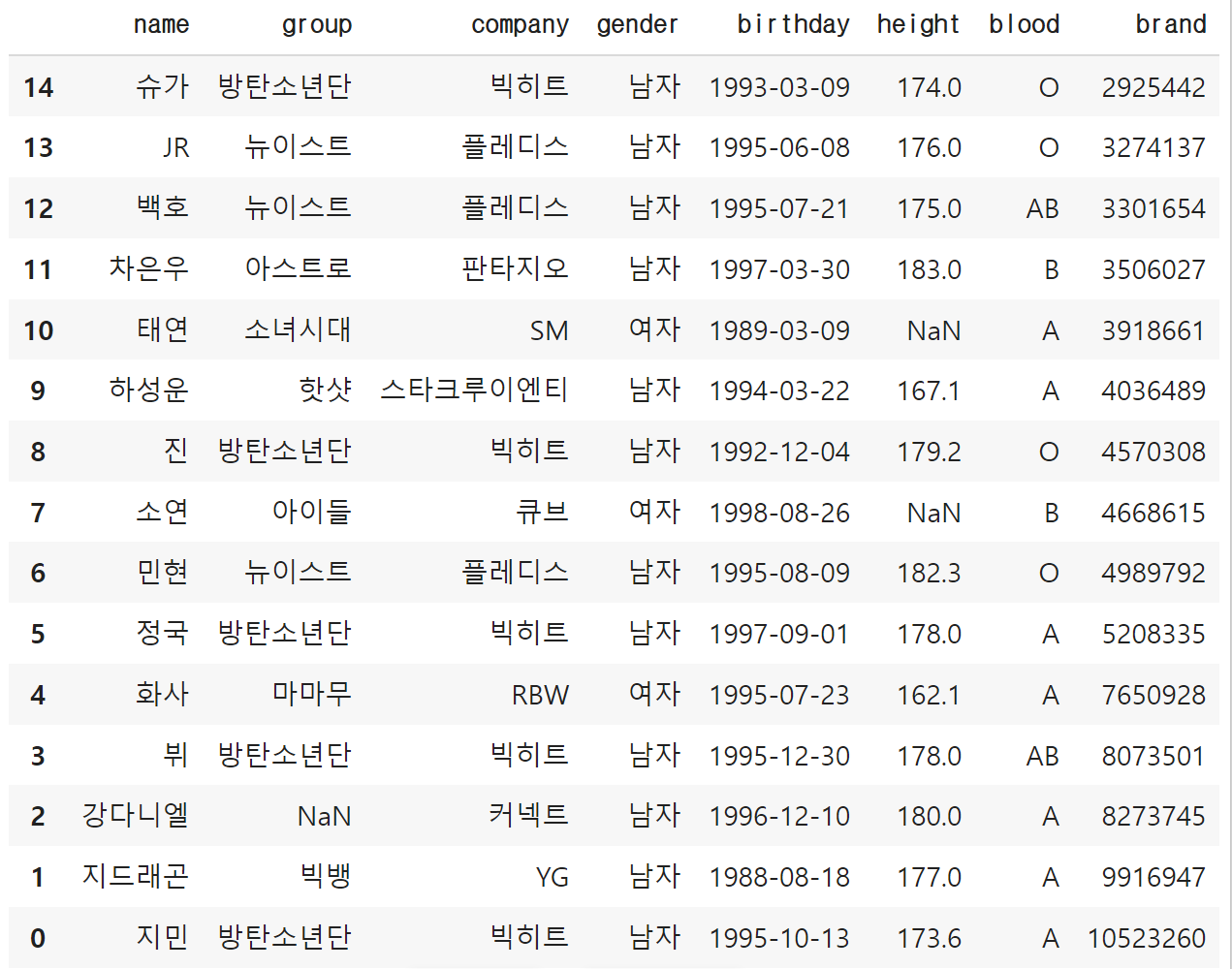
# 값에 따른 오름차순 정렬
df.sort_values(by='height')🌀 결과

#값에 따른 내림차순 정렬
df.sort_values(by='height',ascending=False)🌀 결과

# NaN을 가장 위로 올림: na_position의 기본값은 last
df.sort_values(by='height',na_position='first')🌀 결과

# 1차 정렬: 키(내림차순), 2차 정렬: 브랜드(오름차순)
df.sort_values(by=['height','brand'],ascending=[False,True],na_position='first')🌀 결과

데이터 다루기
df.head()🌀 결과

df['blood']
---------------------------
# 결과
▶ 0 A
1 A
2 A
3 AB
4 A
5 A
6 O
7 B
8 O
9 A
10 A
11 B
12 AB
13 O
14 O
Name: blood, dtype: object1️⃣ 범위 선택
df.head(3)🌀 결과

df[:3]🌀 결과

#loc 인덱싱: 레이블(이름) 인덱싱, 행과 열 모두 인덱싱과 슬라이싱이 가능
df.loc[:,'name']
---------------------------------------------------------------------
▶ 0 지민
1 지드래곤
2 강다니엘
3 뷔
4 화사
5 정국
6 민현
7 소연
8 진
9 하성운
10 태연
11 차은우
12 백호
13 JR
14 슈가
Name: name, dtype: object728x90
반응형
'데이터 분석' 카테고리의 다른 글
| [ 데이터 분석 ] 판다스 (Pandas) (4) | 2023.06.13 |
|---|---|
| [데이터 분석] 연산자 (0) | 2023.06.13 |
| [데이터분석] 넘파이 (Numpy) (0) | 2023.06.12 |